介绍了在spark中Yarn的工作流程和一些总结
流程
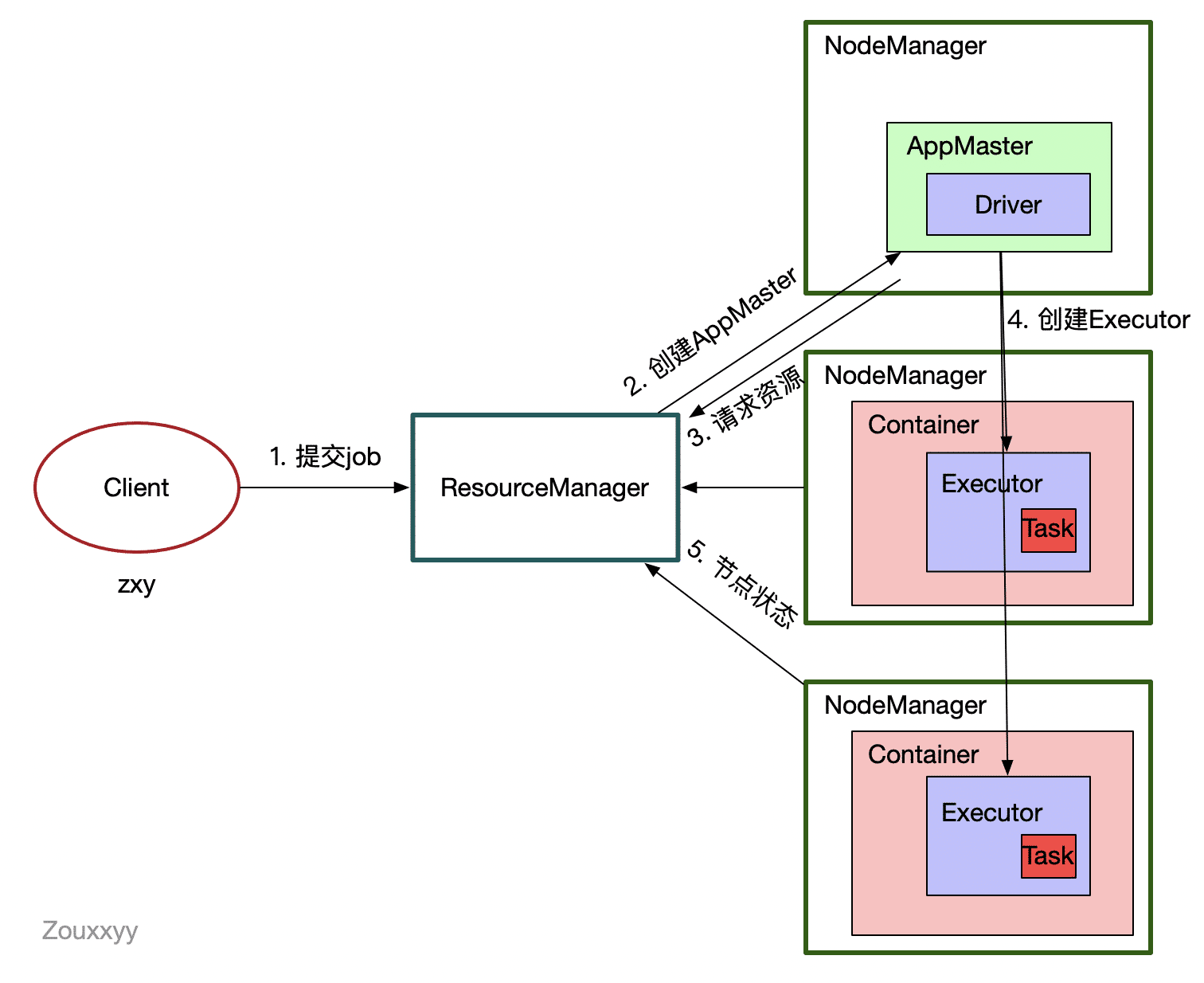
主要流程和Yarn的流程一样,不同的就是紫色部分。这里采用的是spark的yarn-cluster模式,driver在APPMaster中。
细节
解耦思想
-
ResourceManager管理资源调度,与NodeManager直接联系;Driver负责执行计算,与Executor也就是一个个Task直接联系。
-
计算和资源调度解耦:ResourceManager和Driver靠中间件AppMaster联系起来;Executor和NodeManager靠中间件Container联系起来
-
此时计算框架是可插拔的,如:spark计算框架(紫色部分)代替mapreduce。
Client和Cluster模式
spark上yarn有两种管理模式,YARN-Client和YARN-Cluster。
主要区别是:SparkContext初始化位置不同,也就是了Driver所在位置的不同。
| client | master |
|---|---|
| driver在Client上 | driver在AppMaster上 |
| 日志可以直接在Client上看到 | 日志在某个节点上 |
| Client连接不能断开 | Client连接可以断开 |
| 适合交互和调试 | 适合生产环境 |
其它管理模式
local模式
单机模式 --master local[*]
Standalone模式
不用Yarn,用Spark自带的Standalone资源管理器,它把节点分成Master和Worker。类似RM和NM,但它没有AppMaster。也分为Client模式和cluster模式。