简单介绍了hbase的基本原理:数据结构、读写操作、flush、合并与切分
数据结构
逻辑结构
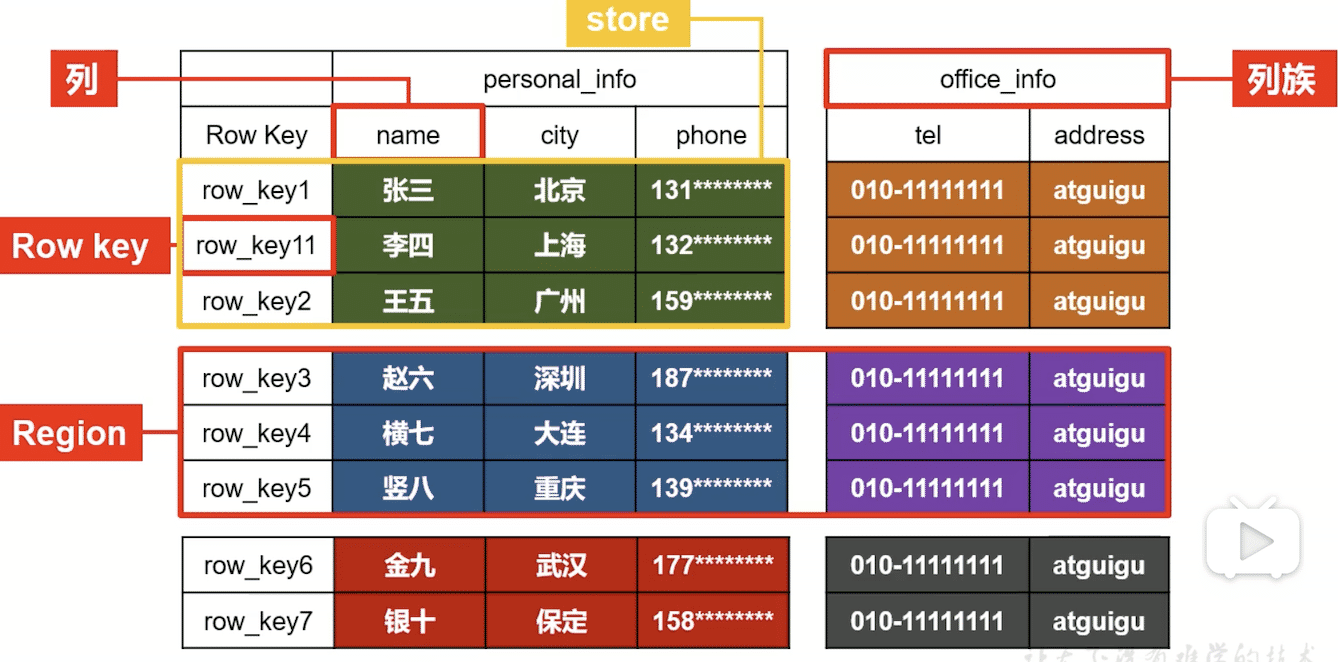
一个namespace可以有多个表,如zxylearn:student,代表zxylearn命名空间下的student表。
一个表可以有多个region,如上图有3个region。一个region一个文件夹。可以预分区(推荐)或者当一个region过大时会自动触发切分。
一个region可以有多个store(按列族划分),如上图有两个列族。一个store一个文件夹,文件夹名是列族名。
一个store可以有多个HFile,flush一次产生一个,可以合并(后面会讲)
HFile中就是具体数据了,逻辑上是一行行序列化的数据。
# HDFS中的一个HFile的完整路径: |
物理结构
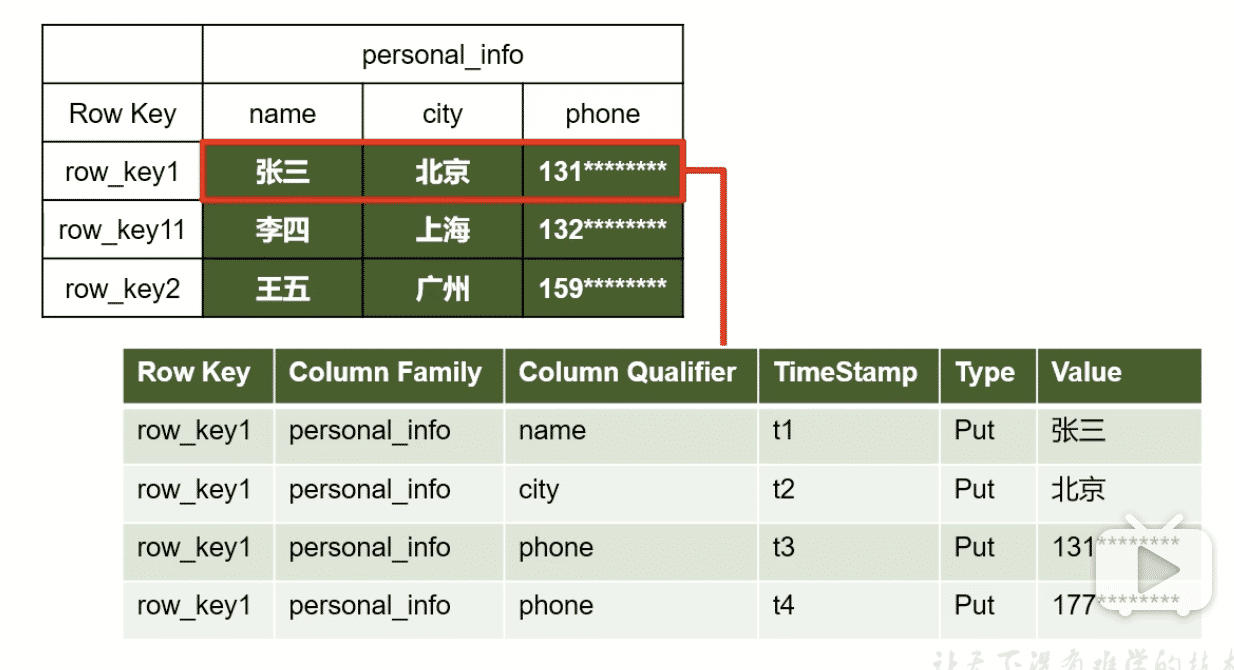
通过指定 'namespace:表名' 和 'Row Key',可查找到数据的列族、列名、timestamp、value
hbase(main):018:0> get 'zxylearn:student','1001' |
写数据流程
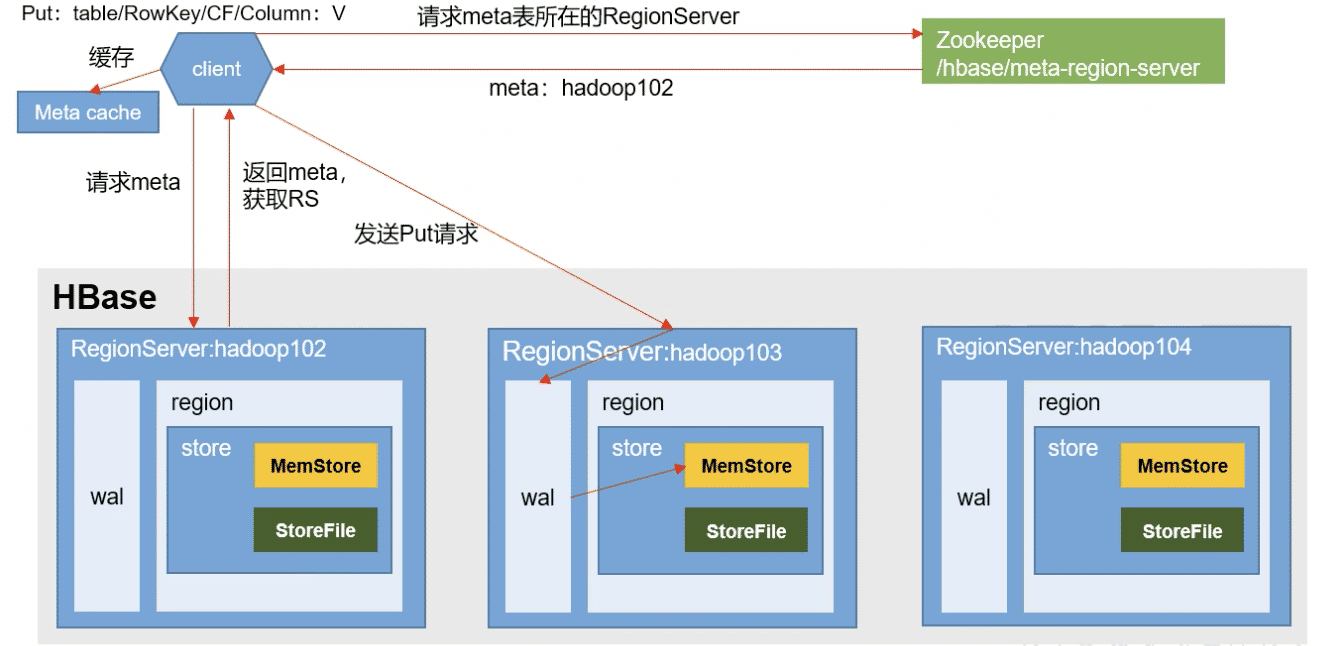
- 客户端向ZK请求返回 元数据表所在的RegionServer地址。(我们可以在ZK客户端中用
get /hbase/meta-region-server看到它) - 客户端接收地址,向它请求返回 待写数据所在的RegionServer地址。(我们可以在hbase客户端用
scan 'hbase:meta'看到它:column=info:server, timestamp=1569658344714, value=localhost:16020) - 向该地址请求写数据。
- 先将写操作记录到操作日志(WAL)中,接着将数据写入内存中。
Flush
可以看出,写数据是将数据写入到内存中。当执行Flush刷写操作时,才会将数据写入磁盘,也就是HDFS中,形成一个HFile。
Flush时机
- 大小超过限制:如RegionServer的全局内存大小,默认是堆大小的40%时刷写;单个region大小,默认128M。
- 时间:从最后一条数据写入后,1h(默认)没有新数据。
Flush细节
- flush会删除过期的数据。假设建表时数据版本数设置为1,那么写入磁盘的的数据最多只有一个版本;如果删除标记是DeleteColumn,那么会删除比它低版本的数据。(删除标记有多种,如 Delete:只删自己;DeleteColumn:删除自己与比自己低的)
- flush不会删除带删除标记的数据。原因:设想,我们原本想删除一条数据,给它打上删除标记。如果flush删除了,假如磁盘中的其它HFile中有该数据的旧版本,那么它们在合并操作(后面会讲)时就不会被删除了。
反正记住这里会干掉不要的数据(版本数与删除标记决定),但不会干掉带删除标记的数据。
读数据流程
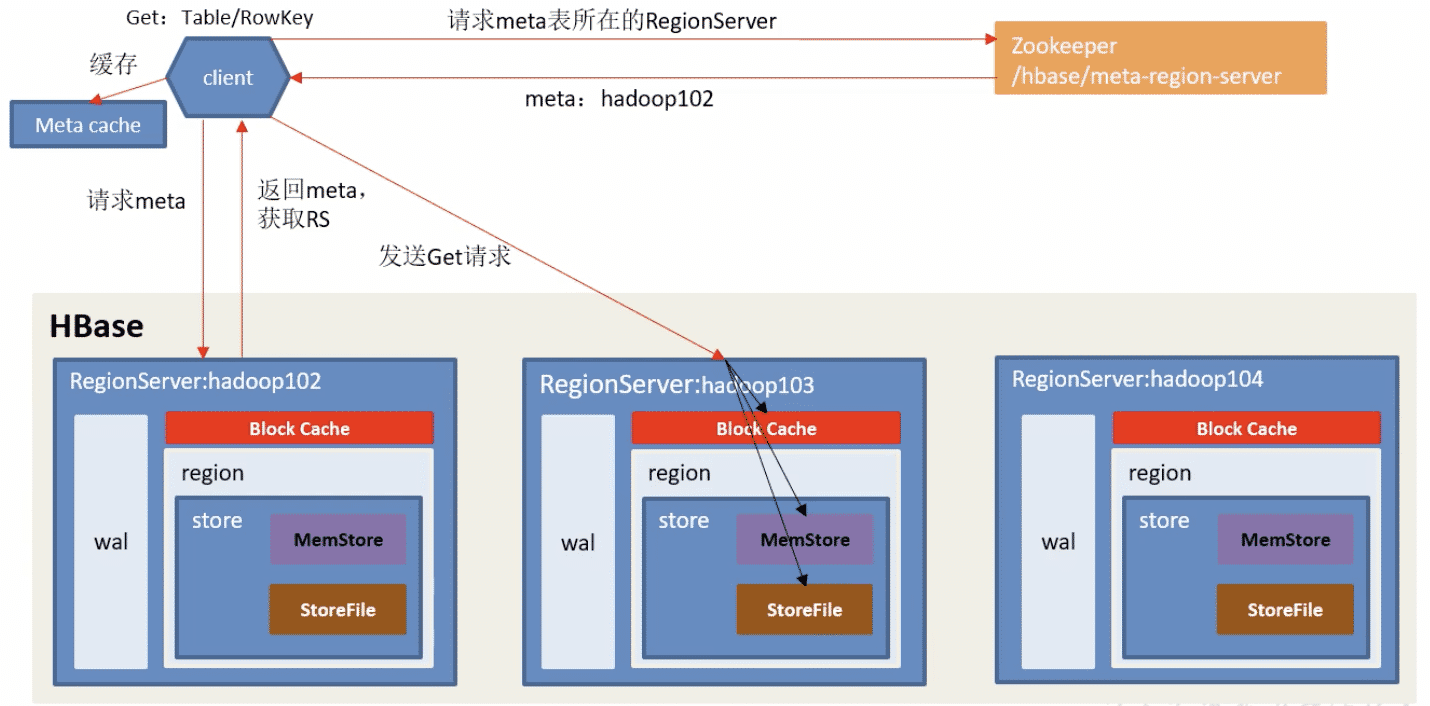
- 找到数据所在RS服务器的流程和写数据基本一样。
- 向该地址请求读数据。
- 读取cache(缓存)和MemStore(内存),查找该数据。
- 如果cache中没有,再去StoreFile(磁盘)中找该数据。
- 取时间戳最新的数据返回,并记录到cache中。
为什么在内存中找到了,还要去磁盘中找?
时间戳的缘故:我们用户自然是查找最新的数据,内存中的数据的时间戳不能保证一定比磁盘中的新,所有要把它们都找到,然后比较返回最新的数据。因此,这导致了hbase读数据比写数据还慢。所以,用cache缓存查到的数据,可以一定程度提高读数据的速度。
compact(合并)与split(切分)
compact(合并)
合并是将若干个小的HFile,合并成一个大的HFile。分Minor Compaction 和 Major Compaction。
-
Minor Compaction 不会清理不要的数据和带删除标记的数据
-
Major Compaction 会清理不要的数据和带标记删除的数据。当HFile数大于等于3时,执行
compact时执行的是它。
清理细节
与flush不同,这里的清理不仅会清除不要的数据,还会清理带删除标记的数据(干掉它,和比它旧的数据)。
split(切分)
切分是将大的region切分成若干个小的region。可以预分区(推荐)或者当一个region过大时会自动触发切分。
为什么推荐只用一个列族呢?
多个列族可能导致小文件过多。假设一个列族的数据的很密集,另一列族很稀疏,那么在触发flush或者split时,密集的列族形成的HFile文件足够大没问题,但是稀疏的生成的就是小文件了,久而久之会形成过多小文件使效率降低。