public void insertRecord(Object recordBase, long recordOffset, int length, int partitionId) throwsIOException {
// for tests assert(inMemSorter != null); // 如果 Sorter 内的数据超过阈值,就发生 spill if (inMemSorter.numRecords() >= numElementsForSpillThreshold) { logger.info("Spilling data because number of spilledRecords crossed the threshold " + numElementsForSpillThreshold); spill(); }
// 检查 inMemSorter中 的数组是否满了,如果满了就扩容 growPointerArrayIfNecessary(); final int uaoSize = UnsafeAlignedOffset.getUaoSize(); // Need 4 or 8 bytes to store the record length. final int required = length + uaoSize; acquireNewPageIfNecessary(required);
public long spill(long size, MemoryConsumer trigger) throwsIOException { if (trigger != this || inMemSorter == null || inMemSorter.numRecords() == 0) { return0L; }
logger.info("Thread {} spilling sort data of {} to disk ({} {} so far)", Thread.currentThread().getId(), Utils.bytesToString(getMemoryUsage()), spills.size(), spills.size() > 1 ? " times" : " time");
writeSortedFile(false); final long spillSize = freeMemory(); // spill 完整。重置 inMemSorter inMemSorter.reset(); // Reset the in-memory sorter's pointer array only after freeing up the memory pages holding the // records. Otherwise, if the task is over allocated memory, then without freeing the memory // pages, we might not be able to get memory for the pointer array. taskContext.taskMetrics().incMemoryBytesSpilled(spillSize); return spillSize; }
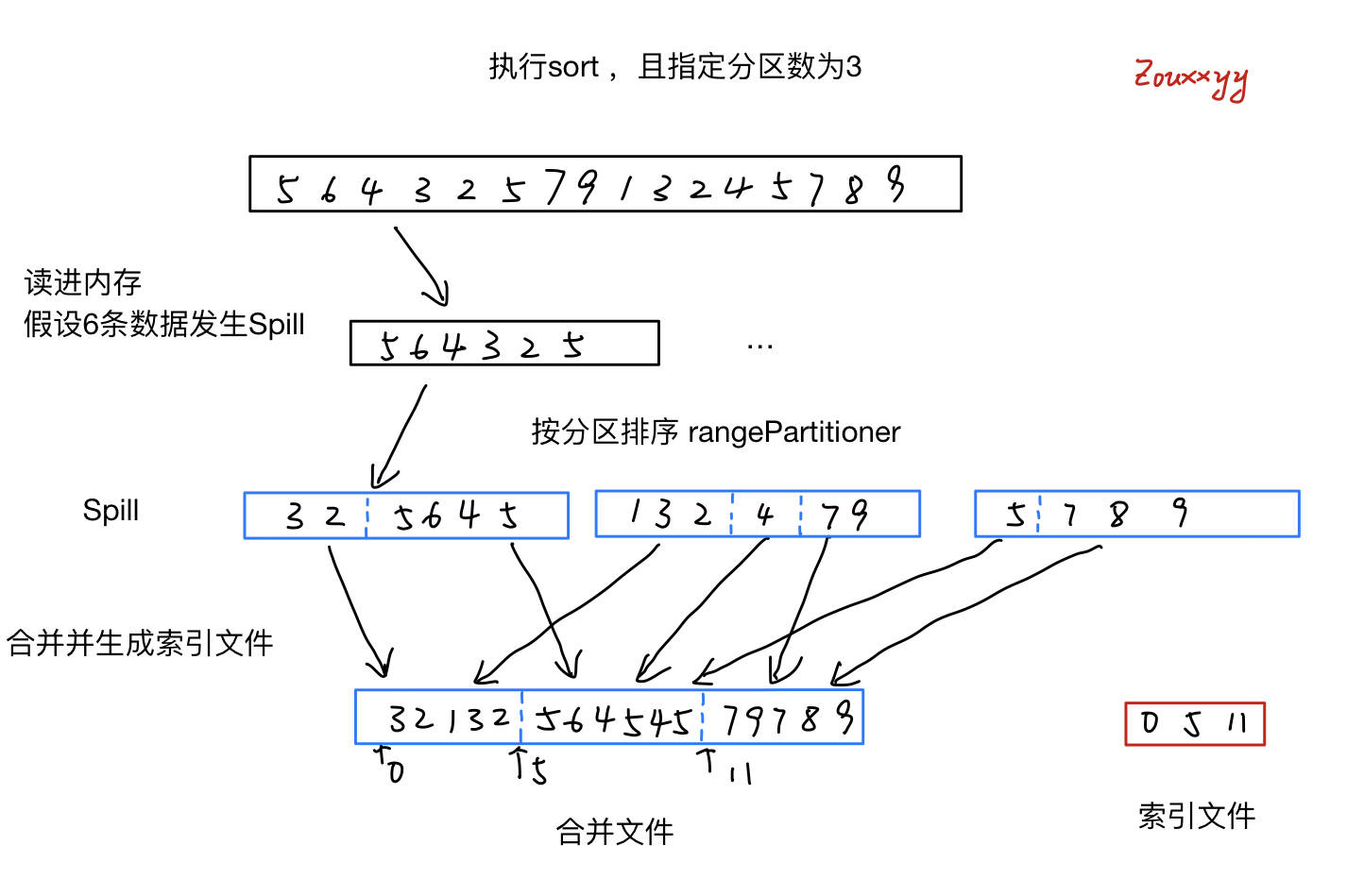
// This call performs the actual sort. // 迭代器:包含分区有序的数据指针(排序在这里进行,有两种排序手段) finalShuffleInMemorySorter.ShuffleSorterIterator sortedRecords = inMemSorter.getSortedIterator(); final byte[] writeBuffer = new byte[diskWriteBufferSize];
int currentPartition = -1; final int uaoSize = UnsafeAlignedOffset.getUaoSize(); while (sortedRecords.hasNext()) { sortedRecords.loadNext(); final int partition = sortedRecords.packedRecordPointer.getPartitionId(); assert (partition >= currentPartition); if (partition != currentPartition) { // Switch to the new partition if (currentPartition != -1) { finalFileSegment fileSegment = writer.commitAndGet(); // 记录每个分区的长度 spillInfo.partitionLengths[currentPartition] = fileSegment.length(); } currentPartition = partition; }
final long recordPointer = sortedRecords.packedRecordPointer.getRecordPointer(); finalObject recordPage = taskMemoryManager.getPage(recordPointer); final long recordOffsetInPage = taskMemoryManager.getOffsetInPage(recordPointer); int dataRemaining = UnsafeAlignedOffset.getSize(recordPage, recordOffsetInPage); long recordReadPosition = recordOffsetInPage + uaoSize; // skip over record length while (dataRemaining > 0) { final int toTransfer = Math.min(diskWriteBufferSize, dataRemaining); Platform.copyMemory( recordPage, recordReadPosition, writeBuffer, Platform.BYTE_ARRAY_OFFSET, toTransfer); writer.write(writeBuffer, 0, toTransfer); recordReadPosition += toTransfer; dataRemaining -= toTransfer; } writer.recordWritten(); }
if (!isLastFile) { // i.e. this is a spill file writeMetrics.incRecordsWritten(writeMetricsToUse.recordsWritten()); taskContext.taskMetrics().incDiskBytesSpilled(writeMetricsToUse.bytesWritten()); } }
long bytesWrittenToMergedFile = 0; // 2重循环,结果是将所有spill文件中同一分区的数据合并,并按分区号排列 for (int partition = 0; partition < numPartitions; partition++) { for (int i = 0; i < spills.length; i++) { final long partitionLengthInSpill = spills[i].partitionLengths[partition]; finalFileChannel spillInputChannel = spillInputChannels[i]; final long writeStartTime = System.nanoTime(); // 将 spill 里的 指定分区数据 写入合并文件中 Utils.copyFileStreamNIO( spillInputChannel, // spill 文件输入流 mergedFileOutputChannel, // 合并文件输出流 spillInputChannelPositions[i], // spill 中 该分区起始位置 partitionLengthInSpill); // spill 中 该分区长度 spillInputChannelPositions[i] += partitionLengthInSpill; writeMetrics.incWriteTime(System.nanoTime() - writeStartTime); bytesWrittenToMergedFile += partitionLengthInSpill; partitionLengths[partition] += partitionLengthInSpill; // 所有 spill 中该分区的总长度 } } if (mergedFileOutputChannel.position() != bytesWrittenToMergedFile) { thrownewIOException( "Current position " + mergedFileOutputChannel.position() + " does not equal expected " + "position " + bytesWrittenToMergedFile + " after transferTo. Please check your kernel" + " version to see if it is 2.6.32, as there is a kernel bug which will lead to " + "unexpected behavior when using transferTo. You can set spark.file.transferTo=false " + "to disable this NIO feature." ); } threwException = false; } finally { for (int i = 0; i < spills.length; i++) { assert(spillInputChannelPositions[i] == spills[i].file.length()); Closeables.close(spillInputChannels[i], threwException); } Closeables.close(mergedFileOutputChannel, threwException); } return partitionLengths; }