overridedefwrite(records: Iterator[Product2[K, V]]): Unit = { // 流程1:根据是否需要 mapSideCombine 选择不同的 sorter sorter = if (dep.mapSideCombine) { newExternalSorter[K, V, C]( context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer) } else { // In this case we pass neither an aggregator nor an ordering to the sorter, because we don't // care whether the keys get sorted in each partition; that will be done on the reduce side // if the operation being run is sortByKey. // 注意 ordering = None,官方解释的很清楚了,对吧 newExternalSorter[K, V, V]( context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer) } // 流程2-3:读取数据 与 spill sorter.insertAll(records)
definsertAll(records: Iterator[Product2[K, V]]): Unit = { // TODO: stop combining if we find that the reduction factor isn't high val shouldCombine = aggregator.isDefined
// 选择是否 combine if (shouldCombine) { // Combine values in-memory first using our AppendOnlyMap val mergeValue = aggregator.get.mergeValue val createCombiner = aggregator.get.createCombiner var kv: Product2[K, V] = null // 从 aggregator 中取出 createCombiner 和 mergeValue,制作成update函数 val update = (hadValue: Boolean, oldValue: C) => { if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2) } while (records.hasNext) { // 计数 + 1 addElementsRead() kv = records.next() // combine 模式使用 PartitionedAppendOnlyMap map.changeValue((getPartition(kv._1), kv._1), update) // 流程3: spill maybeSpillCollection(usingMap = true) } } else { // Stick values into our buffer while (records.hasNext) { addElementsRead() val kv = records.next() // 非 combine 模式使用 PartitionedPairBuffer buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C]) // 流程3: spill maybeSpillCollection(usingMap = false) } } }
protecteddefmaybeSpill(collection: C, currentMemory: Long): Boolean = { var shouldSpill = false // 元素个数是32的整数倍 且 大于 myMemoryThreshold if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) { // Claim up to double our current memory from the shuffle memory pool val amountToRequest = 2 * currentMemory - myMemoryThreshold // 申请内存 val granted = acquireMemory(amountToRequest) myMemoryThreshold += granted // If we were granted too little memory to grow further (either tryToAcquire returned 0, // or we already had more memory than myMemoryThreshold), spill the current collection shouldSpill = currentMemory >= myMemoryThreshold } // spill条件:上面的申请没成功 或者 达到阈值 shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold // Actually spill if (shouldSpill) { _spillCount += 1 logSpillage(currentMemory) // spill 在这里发生 spill(collection) _elementsRead = 0 _memoryBytesSpilled += currentMemory releaseMemory() } shouldSpill }
spill(…)
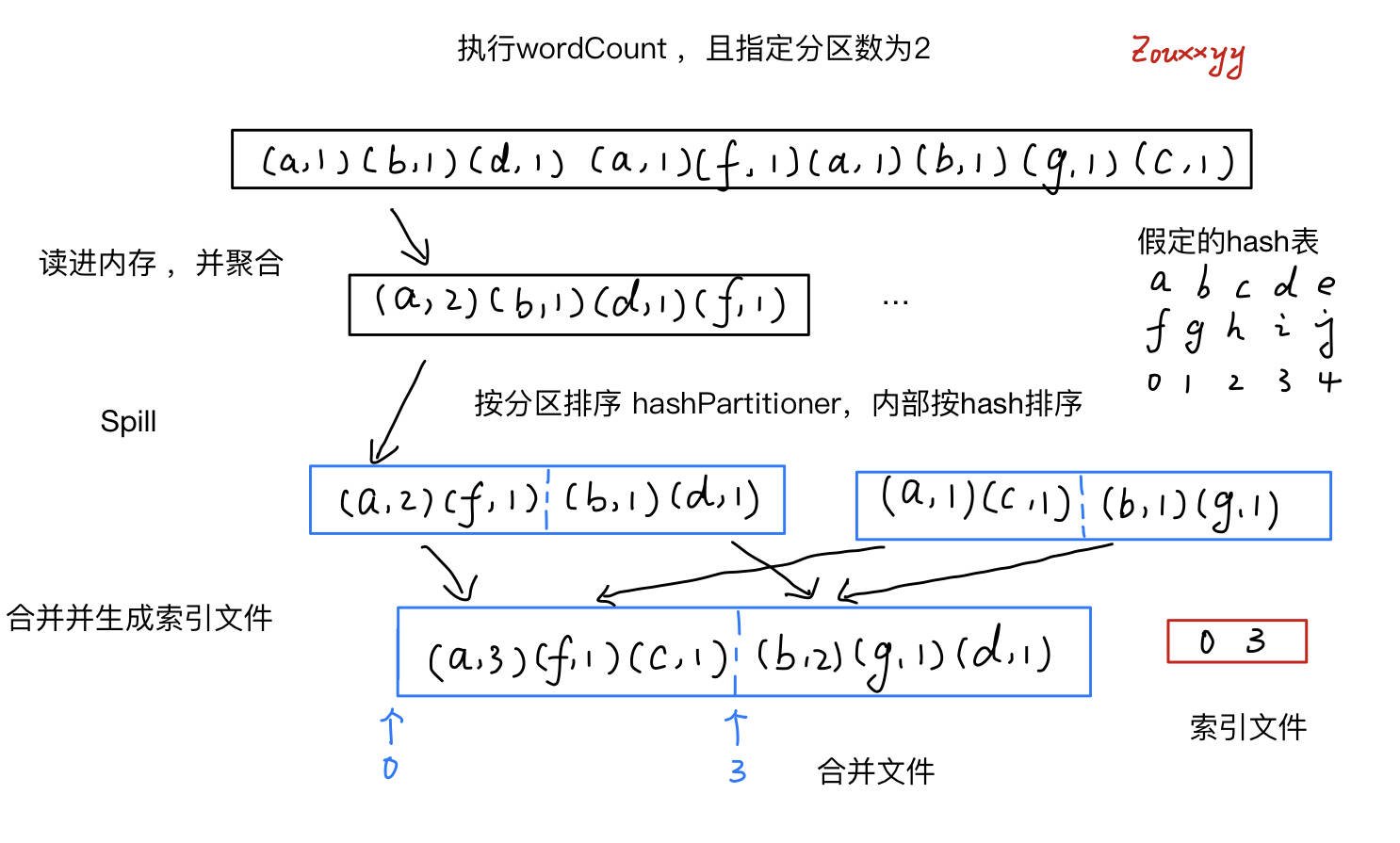
先排序,后spill。排序方面,由于分支不同,有两个排序逻辑。
overrideprotected[this] defspill(collection: WritablePartitionedPairCollection[K, C]): Unit = { // 排序 val inMemoryIterator = collection.destructiveSortedWritablePartitionedIterator(comparator) // spill val spillFile = spillMemoryIteratorToDisk(inMemoryIterator) spills += spillFile }
/** * A comparator for (Int, K) pairs that orders them by only their partition ID. */ defpartitionComparator[K]: Comparator[(Int, K)] = newComparator[(Int, K)] { overridedefcompare(a: (Int, K), b: (Int, K)): Int = { a._1 - b._1 } }
// Track location of each range in the output file val lengths = newArray[Long](numPartitions) val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize, context.taskMetrics().shuffleWriteMetrics)
// 首先知道:collection.destructiveSortedWritablePartitionedIterator(comparator) 用这玩意获取内存中的数据(未被spill),后面多次用到它 if (spills.isEmpty) { // Case where we only have in-memory data // 只有内存文件,刷进内存即可(当然排序什么的还是要的,和上一步一样的规则) val collection = if (aggregator.isDefined) map else buffer val it = collection.destructiveSortedWritablePartitionedIterator(comparator) while (it.hasNext) { val partitionId = it.nextPartition() while (it.hasNext && it.nextPartition() == partitionId) { it.writeNext(writer) } val segment = writer.commitAndGet() // 记录分区长度 lengths(partitionId) = segment.length } } else { // 合并操作在这里:this.partitionedIterator,内部调用 merge() for ((id, elements) <- this.partitionedIterator) { if (elements.hasNext) { for (elem <- elements) { writer.write(elem._1, elem._2) } val segment = writer.commitAndGet() lengths(id) = segment.length } } }
privatedefmerge(spills: Seq[SpilledFile], inMemory: Iterator[((Int, K), C)]) : Iterator[(Int, Iterator[Product2[K, C]])] = { val readers = spills.map(newSpillReader(_)) val inMemBuffered = inMemory.buffered (0 until numPartitions).iterator.map { p => // 很明显这兄弟函数式编程写的很6 // 主要就是把 spill文件 和 内存文件 同分区的数据放到一起计算(3种计算情况)。其实和以前的2重循环是一个意思 val inMemIterator = newIteratorForPartition(p, inMemBuffered) val iterators = readers.map(_.readNextPartition()) ++ Seq(inMemIterator) if (aggregator.isDefined) { // Perform partial aggregation across partitions // 聚合:(分有无 ordering 两种情况) (p, mergeWithAggregation( iterators, aggregator.get.mergeCombiners, keyComparator, ordering.isDefined)) } elseif (ordering.isDefined) { // No aggregator given, but we have an ordering (e.g. used by reduce tasks in sortByKey); // sort the elements without trying to merge them // 只排序:对它们进行归并排序。 // 说实话,我不觉得它会进这一分支。因为我多次强调过没有 aggregator 就必定没有 ordering (p, mergeSort(iterators, ordering.get)) } else { // 啥都不要,直接把同分区文件 flatten (p, iterators.iterator.flatten) } } }
mergeWithAggregation(…)
聚合:(分有无 ordering 两种情况)
privatedefmergeWithAggregation( iterators: Seq[Iterator[Product2[K, C]]], mergeCombiners: (C, C) => C, comparator: Comparator[K], totalOrder: Boolean) : Iterator[Product2[K, C]] = { if (!totalOrder) { // We only have a partial ordering, e.g. comparing the keys by hash code, which means that // multiple distinct keys might be treated as equal by the ordering. To deal with this, we // need to read all keys considered equal by the ordering at once and compare them. // 无 ordering ,comparator 是 hash比较器。hash值相同的是key相同的必要条件 newIterator[Iterator[Product2[K, C]]] { val sorted = mergeSort(iterators, comparator).buffered
// Buffers reused across elements to decrease memory allocation val keys = newArrayBuffer[K] val combiners = newArrayBuffer[C]
overridedefhasNext: Boolean = sorted.hasNext
overridedefnext(): Iterator[Product2[K, C]] = { if (!hasNext) { thrownewNoSuchElementException } keys.clear() combiners.clear() val firstPair = sorted.next() keys += firstPair._1 combiners += firstPair._2 val key = firstPair._1 // hash值相等 while (sorted.hasNext && comparator.compare(sorted.head._1, key) == 0) { val pair = sorted.next() var i = 0 var foundKey = false while (i < keys.size && !foundKey) { // 注意 == 。 scala 就是用 == 比较对象相等的 if (keys(i) == pair._1) { // key 相等 就合并 combiners(i) = mergeCombiners(combiners(i), pair._2) foundKey = true } i += 1 } if (!foundKey) { keys += pair._1 combiners += pair._2 } }
// Note that we return an iterator of elements since we could've had many keys marked // equal by the partial order; we flatten this below to get a flat iterator of (K, C). keys.iterator.zip(combiners.iterator) } }.flatMap(i => i) } else { // We have a total ordering, so the objects with the same key are sequential. // 有 ordering:先归并排序,再把有相同的key的元素聚合就行了 newIterator[Product2[K, C]] { // 归并排序 val sorted = mergeSort(iterators, comparator).buffered
overridedefhasNext: Boolean = sorted.hasNext
overridedefnext(): Product2[K, C] = { if (!hasNext) { thrownewNoSuchElementException } val elem = sorted.next() val k = elem._1 var c = elem._2 // key 相等 就合并 while (sorted.hasNext && sorted.head._1 == k) { val pair = sorted.next() c = mergeCombiners(c, pair._2) } (k, c) } } } }