介绍了在spark中DataFrame和DataSet,以及它们之间的相互转换。
概念分析
DataFrame
类似传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。也就是普通RDD添加结构化信息得到。
DataSet
强类型的,存储的是对象。由DataFrame添加类属性得到。
相同点
-
都是基于RDD的,所以都有RDD的特性,如懒加载,分布式,不可修改,分区等等。但执行sql性能比RDD高,因为spark自动会使用优化策略执行。说白了你手撸的干不过开发者写的。
-
均支持sparksql的操作,还能注册临时表,进行sql语句操作
-
DataFrame和Dataset均可使用模式匹配获取各个字段的值和类型 -
DataFrame也叫Dataset[Row],每一行的类型是Row
不同点
因为DataFrame也叫Dataset[Row],所以我们理解了Row和普通对象的区别就好办了
-
Row的数据结构类似一个数组,只有顺序,切记。普通对象的数据结构也就是对象。
-
因此,访问Row只能通过如:
getInt(i: Int)解析数据 或者 通过模式匹配得到数据;而普通对象可以通过.号 直接访问对象中成员变量。 -
同理,Row中数据没类型,没办法在编译的时候检查是否有类型错误(弱类型的概念);相反普通对象可以(强类型)。
RDD、DataFrame和DataSet转换
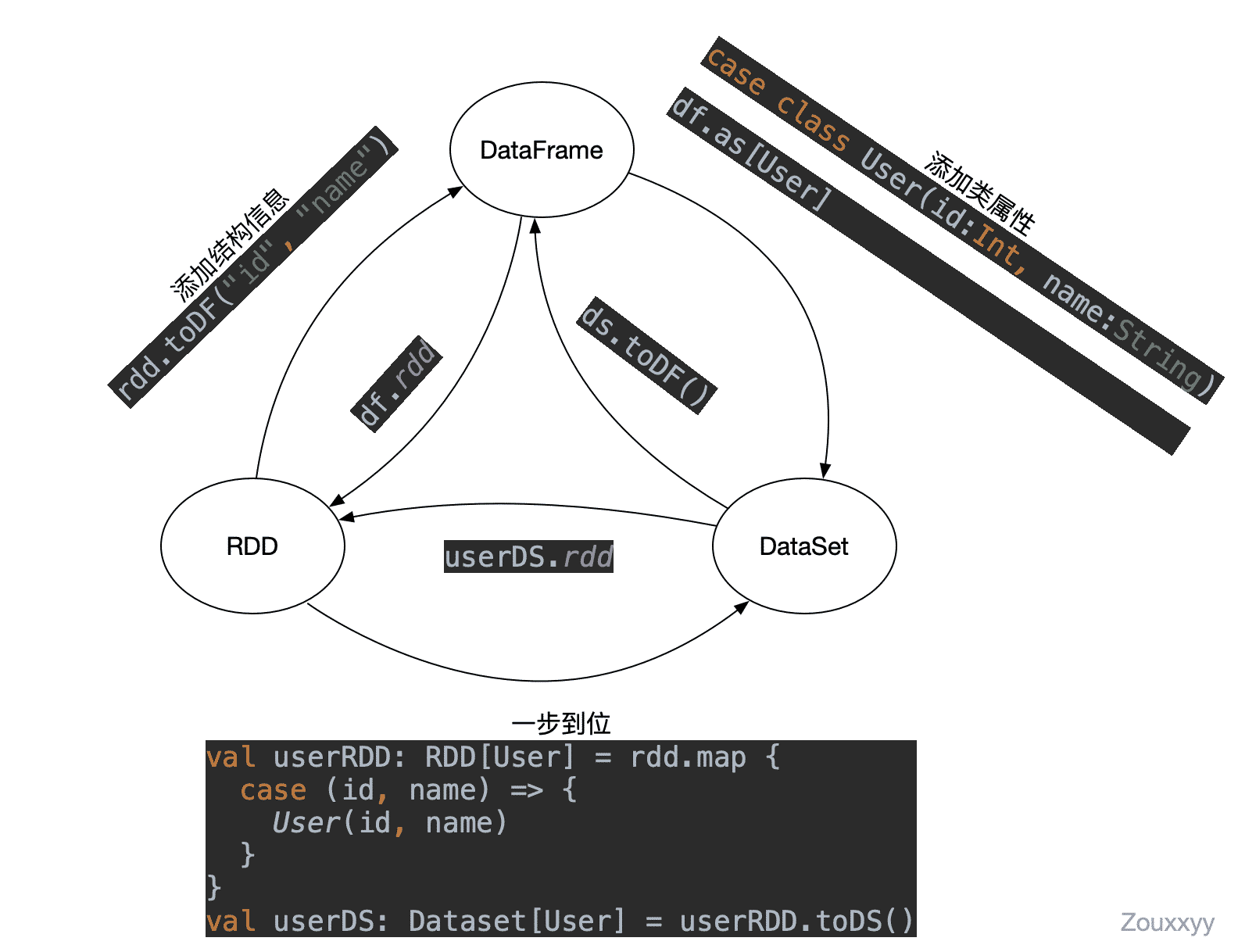
注意
-
原始RDD类型是
RDD[(Int, String)] -
DataFrame -> RDD 时,变成了
RDD[Row] -
DataSet -> RDD时,变成了
RDD[User]
使用
SQL风格(主要)
- 创建一个DataFrame
val df: DataFrame = spark.read.json("people.json") |
- 对DataFrame创建一个临时表(临时表是Session范围内有效,也可以创建全局的)
df.createOrReplaceTempView("people") |
- 通过SQL语句实现对表的操作
spark.sql("SELECT * FROM people").show() |
DSL风格(次要)
- 创建一个DataFrame
val df: DataFrame = spark.read.json("people.json") |
- 使用DataFrame的api
df.select("name").show() |
df.select($"name", $"age" + 1).show() |
小结
DataFrame和Dataset都是为了方便我们执行sql的,因此当我们把数据转化成它们之后,写好sql逻辑,剩下的就交给咱们spark吧!