它俩的对象和方法较多,需要耐心反复看。
MemoryManager
限制存储内存(storage)和执行内存(execution)的大小的管理器,有两种实现:StaticMemoryManager 和 UnifiedMemoryManager。
-
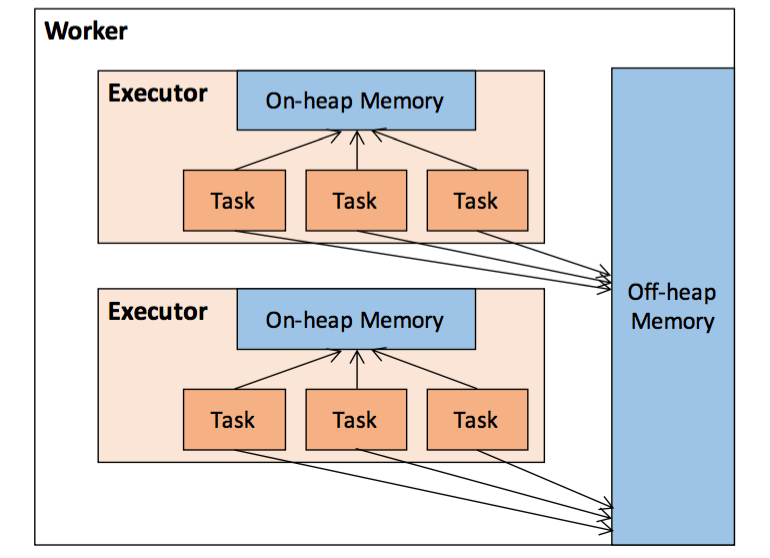
一个Executor,一个JVM,一个MemoryManager,多个Task
-
同一Executor的Task可共享堆内堆外内存,而同一个节点的不同Executor的Task只能共享堆外内存
-
只能共享存储内存,计算内存肯定无法共享
核心依赖对象——MemoryPool
它用于统计每个Executor内存使用情况的类(它并不是去查内存,只是记录,比如要用内存时就把数字增加,减时就把数字减少),具体实现分两种:StorageMemoryPool 和 ExecutionMemoryPool,它们每个又分堆内和堆外内存。基本方法有:poolSize、memoryUsed、memoryFree(_poolSize - memoryUsed),看名知意。
-
StorageMemoryPool:除了有统计功能,并且还会在需要的内存不够时,通知MemoryStore调用evictBlocksToFreeSpace驱逐内存(发现不够,会先向执行内存借,如果借不到再驱逐。这部分代码在MemoryManager中)。 -
ExecutionMemoryPool:相对内存池复杂点,由于存储内存对于同一个Executor的多个Task来说是共享的,而执行内存是不共享的。因此,其内部需要维护一个HashMap,存储每个Task使用的执行内存。细节1: 内部的
acquireMemory和releaseMemory之间采用wait()和notifyAll()机制 :在内存不够时acquireMemory会触发 wait,而当releaseMemory时,notifyall。细节2: 每个Task最少到分执行内存的 1 / 2N,当超过1 / N时,不再允许申请。
细节3:
acquireMemory内部有个回调函数maybeGrowPool:当执行内存不足时,从存储内存中借它剩余的,或者要它归还从执行内存中借走的。
从这里也可以发现,执行内存可以要回被借走的,而存储内存不可以,这就是后面要说的动态占用规则之一。
注意:MemoryPool里的操作,都加了object lock(MemoryManager)
UnifiedMemoryManager
spark 1.6 后统一使用UnifiedMemoryManager,它的进步是存储内存和执行内存可以动态占用。
内存划分
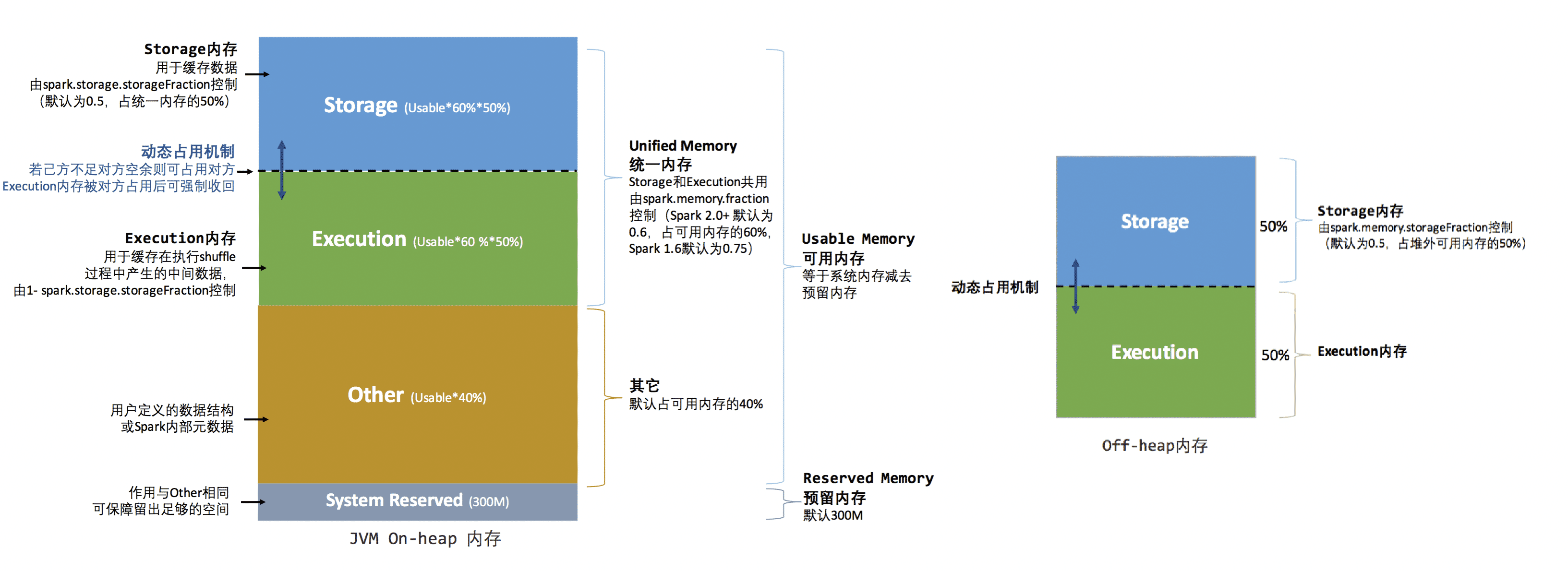
堆内内存(spark.executor.memory JVM内存)
- 存储(storage)内存:(堆内内存 - 预留) * 0.6
spark.memory.fraction* 0.5spark.memory.storageFraction,用于 cache、broadcast 等 - 执行(executor)内存:(堆内内存 - 预留) * 0.6
spark.memory.fraction* (1 - 0.5spark.memory.storageFraction,用于计算,如shuffles、join、sorts and aggregations - 其它内存:(堆内内存 - 预留) * (1 - 0.6
spark.memory.fraction) - 预留内存:
RESERVED_SYSTEM_MEMORY_BYTES规定 300M
堆外内存(spark.memory.offHeap.size)
- 存储内存:堆外内存 * 0.5
spark.memory.storageFraction - 执行内存:堆外内存 * (1 - 0.5
spark.memory.storageFraction)
动态占用
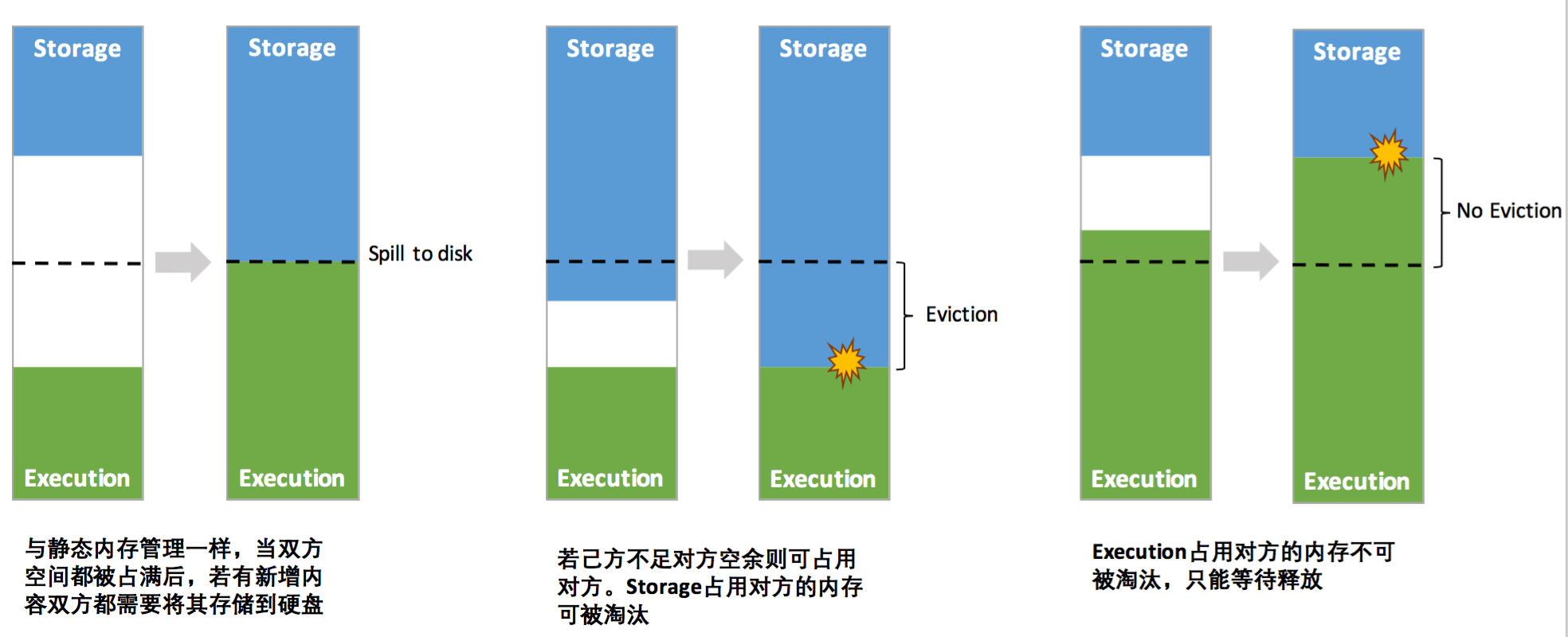
存储内存可以尽可能多地借用执行内存中的free内存,但是当执行池需要这部分内存时,会把该部分内存池中的对象从内存中驱逐出,直到满足执行池的内存需求。
执行内存也可以尽可能多地借用存储内存中的free内存,不同的是,执行内存不会被存储池驱逐出内存。
也就是说,缓存block时可能会因为执行池占用了大量的内存池,不能释放导致缓存block失败,在这种情况下,新的block会根据StorageLevel做相应处理(如 spill 磁盘或干脆丢弃以前的)。
注意 MemoryManager 里的acquireMemory操作都加了synchronized
MemoryStore
负责将blocks写入内存及删改查操作,写入结构为反序列化的Java对象数组,或者序列化的ByteBuffers
核心依赖对象——MemoryEntry
块在内存中的抽象表示,也就是数据在存储内存中存储方式,有两种实现:DeserializedMemoryEntry和SerializedMemoryEntry
DeserializedMemoryEntry:存储的数据结构是Array[T],只适用于堆内
SerializedMemoryEntry:存储的数据结构是ChunkedByteBuffer(物理上存储为多个块而不是单个块上的连续数组),适用于堆内和堆外
采用数组的数据结构很好的解决存储内存碎片问题:通常RDD 的 record 是 在 other内存中的是不连续空间,当要缓存时(也就是存到存储内存中),会将其由不连续的存储空间转换为连续的存储空间(数组)。
核心成员
entries:一个 LinkedHashMap (BlockId -> MemoryEntry),blocks 存入 MemoryEntry,同时建立 BlockId 和 MemoryEntry 的映射关系。注意LinkedHashMap本身不是线程安全的,因此对其并发访问都要加锁。MemoryStore的核心其实就是对entries的增删改查。
onHeapUnrollMemoryMap 和 offHeapUnrollMemoryMap:(BlockId -> 使用的 UnrollMemory 的大小)
核心方法:
putBytes
序列化ByteBuffer的写入:在写入前,先调用MemoryManager.acquireStorageMemory()申请所需的内存,再将ChunkedByteBuffer封装进SerializedMemoryEntry,最后将该MemoryEntry放入entries映射。
putIterator[T]
迭代器对象的写入,根据入参 valuesHolder的不同,决定写成对象还是字节
开始时,先初始化(申请)一部分内存(spark.storage.unrollMemoryThreshold 默认1M),将迭代器对象逐渐存入valuesHolder,并且每添加memoryCheckPeriod个元素就检查一次valuesHolder中数据占用的内存,如果超过了申请的内存就继续申请UnrollMemory(由memoryGrowthFactor参数控制申请大小,这种递增的方式避免OOM)。将全部元素存入valuesHolder后,使用它的build方法生成MemoryEntry(如果是堆内模式内部就是将SizeTrackingVector转成数组),接着release掉申请的unroll内存,最后申请整体大小的Storage内存。化零为整,这个零它就是UnrollMemory,现在知道UnrollMemory是啥了吧,它就是个工具人。
该函数,由下面两个函数调用。
putIteratorAsValues
将迭代器对象 写成对象,使用的valuesHolder是 DeserializedValuesHolder
该方法的重点把握DeserializedValuesHolder,其内部有两个数据结构:SizeTrackingVector 和 Array;SizeTrackingVector 实现了SizeTracker接口,通过采样估计的方式得到其占用大小(估计值)。数据存入DeserializedValuesHolder其实是写入到SizeTrackingVector中,等待全部写完,再使用getBuilder方法,将SizeTrackingVector转成Array,再转成DeserializedMemoryEntry。
putIteratorAsBytes
将迭代器对象 写成字节,使用的valuesHolder是 SerializedValuesHolder
SerializedValuesHolder 内部是各种流,且用到了serializerManager,暂时不想了解过深,只要知道每次write时流内部会记录size,因此得到的总size是精确的。其内部的build方法,将数据封装成SerializedMemoryEntry。
getBytes、getValues、remove
读删操作就很简单了,直接根据blockId 对entries中的Map进行读删即可
getBytes 的返回值是 ChunkedByteBuffer ,getValues 的返回值是 Iterator[T],分别对应entry的2种数据结构
evictBlocksToFreeSpace
是不是很熟悉这名字,驱除存储内存时用的就是它。
调用时机
- 存储内存不足(自己的不够并且借执行内存的也不够 或者 被执行内存占用很多)
- 执行内存不足时,需要回收被存储内存占用的
回收限制
- 不能是同一个 RDD的 block,避免循环淘汰
- memoryMode一致,即同属堆内或者堆外
- Block 不能处于被读状态
- LRU(最近最少使用):这是 entries 也就是 LinkedHashMap自带的功能
小结
MemoryManager 用于对内存划分,同时实现执行内存和存储内存的动态占用。这一切都是逻辑上的,它其实就是计数员,MemoryPool 就是它的账本。当你需要使用执行内存或者存储内存时,你要向它汇报,它会对下帐本告诉你可不可分到,接着对账本修改。
MemoryStore 负责将数据写入存储内存以及后续的读取与删除,数据结构就是一个LinkedHashMap。说白了它就是个仓库,存缓存,存广播等等。
你可能会有个疑问,MemoryManager不是划了执行内存和存储内存嘛,都是关于存储内存的,那么执行内存的操作去哪啦?它与TaskMemoryManager和MemConsumer有关。