本文是对 java 集合的总结。书的思路是将接口与实现分开讲;然后从父讲起,再讲子对父的提升。我觉得这种方式很好理解加记忆,所以本文也是这样整理的。
集合框架
主要思路是让接口与实现分离
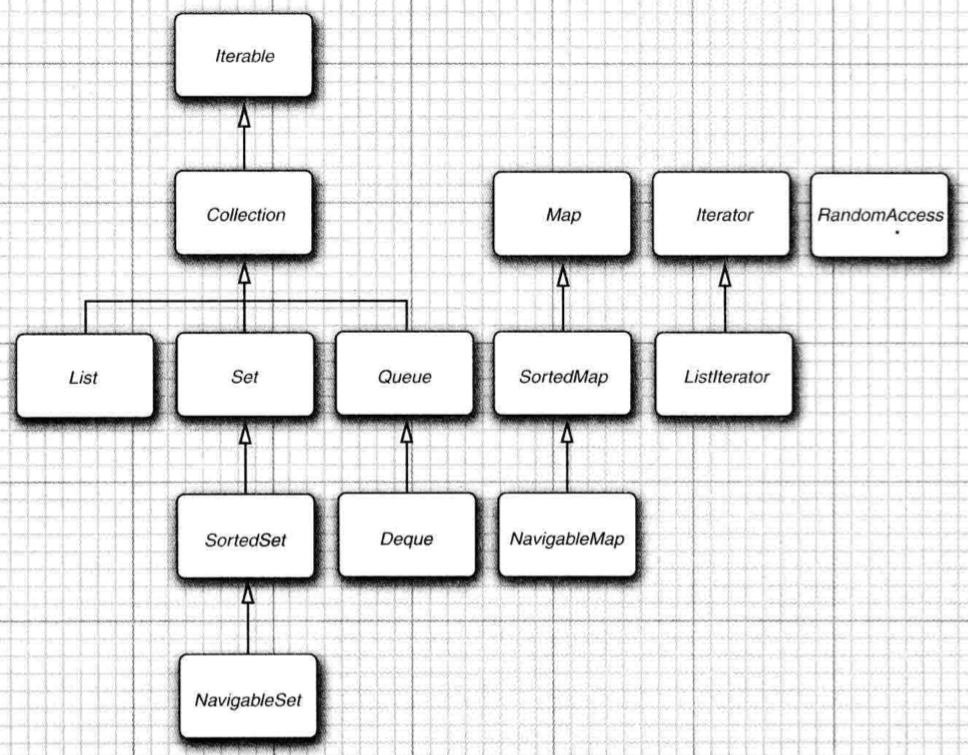
集合框架的接口:两个基本接口 Collection 和 Map
集合框架的类:

接口
两个基本接口:Collection 和 Map
Collection
以下是Collection接口内的一些方法
public abstract interface class java.util.Collection |
可以看出来就是 大小,加,删,是否含某个元素,是否空 等等,这些集合最基础的功能
Collection中有Iterator接口
public abstract interface class java.util.Iterator |
Map
以下是Map接口内的一些方法
public abstract interface class java.util.Map |
可以看出来就是 大小,加映射,删映射,用键查值,是否空 等等,这些映射最基础的功能。还有些视图的部分,下篇文章具体讲
Collection的子接口
List
有序集合,新加支持随机访问功能:
- add(n, 元素)
- remove(n)
- get(n)
- set(n, 元素)
Set
- 元素不重复,所以要适当的定义
equals方法; - 子接口
SortedSet,故名思义是排好序的,所以要适当的定义比较器 SortedSet的子接口NavigableSet中设计了一些搜素,遍历的方法
Queue
- 入队尾,出对头
- 子接口
Qeque双端队列,两头都可以出入
Map的子接口
其实和Set差不多
- 子接口
SortedMap,故名思义是排好序的,所以要适当的定义比较器 SortedMap的子接口NavigableMap中设计了一些搜素,遍历的方法
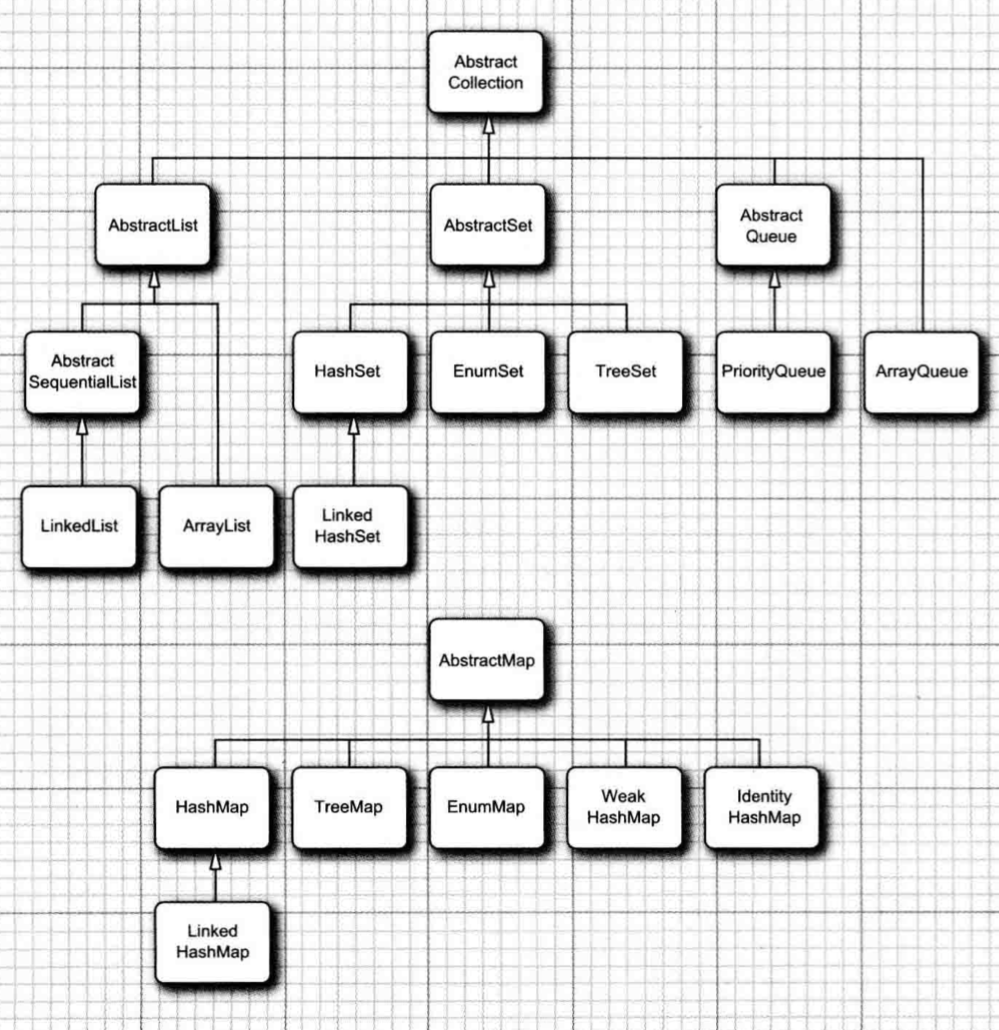
对接口的实现
List
LinkedList(链表)
java中的链表都是双向的(有前驱后驱)。重点讲下它的迭代器ListIterator
- 初始位置: |ABCD
iter.next: A|BCDiter.previous: |ABCDiter.add: 把元素加到光标|之前,注意是之前iter.remove必须在it.next或it.previous使用之后使用,把光标经过的元素删除
链表使用注意:
- 使用链表是可以减少在列表中间插入删除元素所付出的代价。
- 避免使用以整数索引链表中的位置,这样效率很低
ArrayList(数组列表)
ArrayList: 动态泛型数组列表,可以自动调节数组容量。当需要随机访问时使用它效率更高,不用链表。
讲下capacity和size的区别:
new ArrayList<>(100)100 是capacity,是初始容量,如果实际size超过它,容量会自动增加array.size()返回的是数组列表内元素实际的个数。
p.s. 这和c++的 vector 很像
Set
HashSet(散列集)
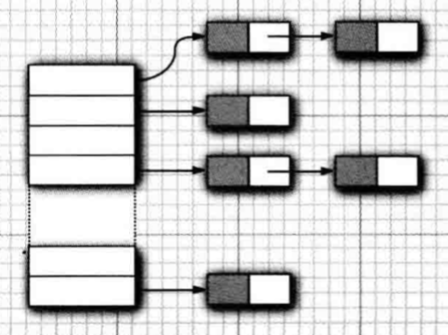
HashSet: 基于散列表的Set,内部用链表数组实现。初始化时可以指定容量和装填因子。- 由于HashSet访问是随机的,所以当不需要关心集合中的顺序时才使用它。
- 子类
LinkedHashSet,里面的元素之间是双向链表,迭代器是按插入顺序进行访问的。
TreeSet(树集)
-TreeSet: 实现SortedSet接口,内部基于红黑树。由于是有顺序的,所以用户一般要自定义比较器。迭代器是按排序顺序进行访问的。
- 当不需要顺序时,用
HashSet,因为它更快。 - 可以实现升级版
NavigableSet接口,higher(v),lower(v),pollFirst(),pollLast(),反向迭代 等等。
Queue
一般用它的升级版Deque,而Deque可以由ArrayDeque和LinkedList实现。下面主要介绍PriorityQueue
PriorityQueue(优先级队列)
PriorityQueue:优先级队列,内部基于堆(heap)。- 按任意顺序插入,却总是按排序顺序输出最小值。
PriorityQueue<Type> pq = new PriorityQueue();,从左边可以看出这货是类。
Map
HashMap
- 顾名思义和
HashSet差不多,只不过是对建进行散列。 - 子类
LinkedHashMap,注意链表散射映射,迭代器是按访问顺序进行访问的。每次调用 get 或 put, 受到影响的条目将从当前的位置删除,并放到条目链表的尾部。
TreeMap
- 顾名思义和
HashMap差不多,只不过是对建进行红黑树排序。 - 同样 当不需要顺序时,用
HashMap,因为它更快.
一些技巧:
- 遍历Map:
scores.forEach((k, v) -> // 访问 k, v 的最快方法 |
- 用 Map 计数:
scores.put("Jack", scores.getOrDefault("Jack", 0) + 1); // 方法1 |
WeekHashMap
弱散列映射:当对键的唯一引用来自散列条目时,这一数据结构将与垃圾回收器协同工作一起删除键 / 值对。也就是当某个值没用了它会被自动回收。
IdentityHashMap
IdentityHashMap中 键的散列值 不是用 hashCode 函数计算的,而是用System.identityHashCode方法计算的(Object.hashCode方法根据对象的内存地址来计算散列码时所使用的方式)。- 所以,在对两个对象进行比较时,IdentityHashMap 使用 == , 而不使用equal。也就是不同的键对象,即使内容相同,也被视为是不同的对象。
- 在实现对象遍历算法 (如对象串行化)时,可以它用来跟踪每个对象的遍历状况。
遗留的集合
看看就好,遇到时再查书
本文示例代码:github