介绍了在spark中窄、宽依赖的划分以及任务划分
窄依赖和宽依赖
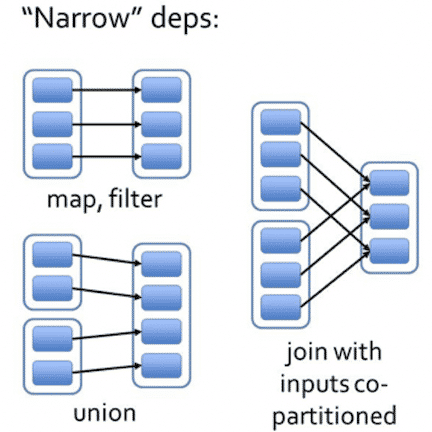
窄依赖
- 每一个父RDD的Partition最多被子RDD的一个Partition使用
- 独生子女:一个爹RDD只有一个子
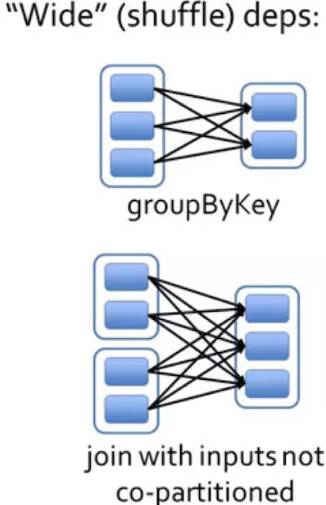
宽依赖
- 每一个父RDD的Partition被子RDD的多个Partition使用,伴随shuffle
- 超生:一个爹RDD有多个子
任务划分
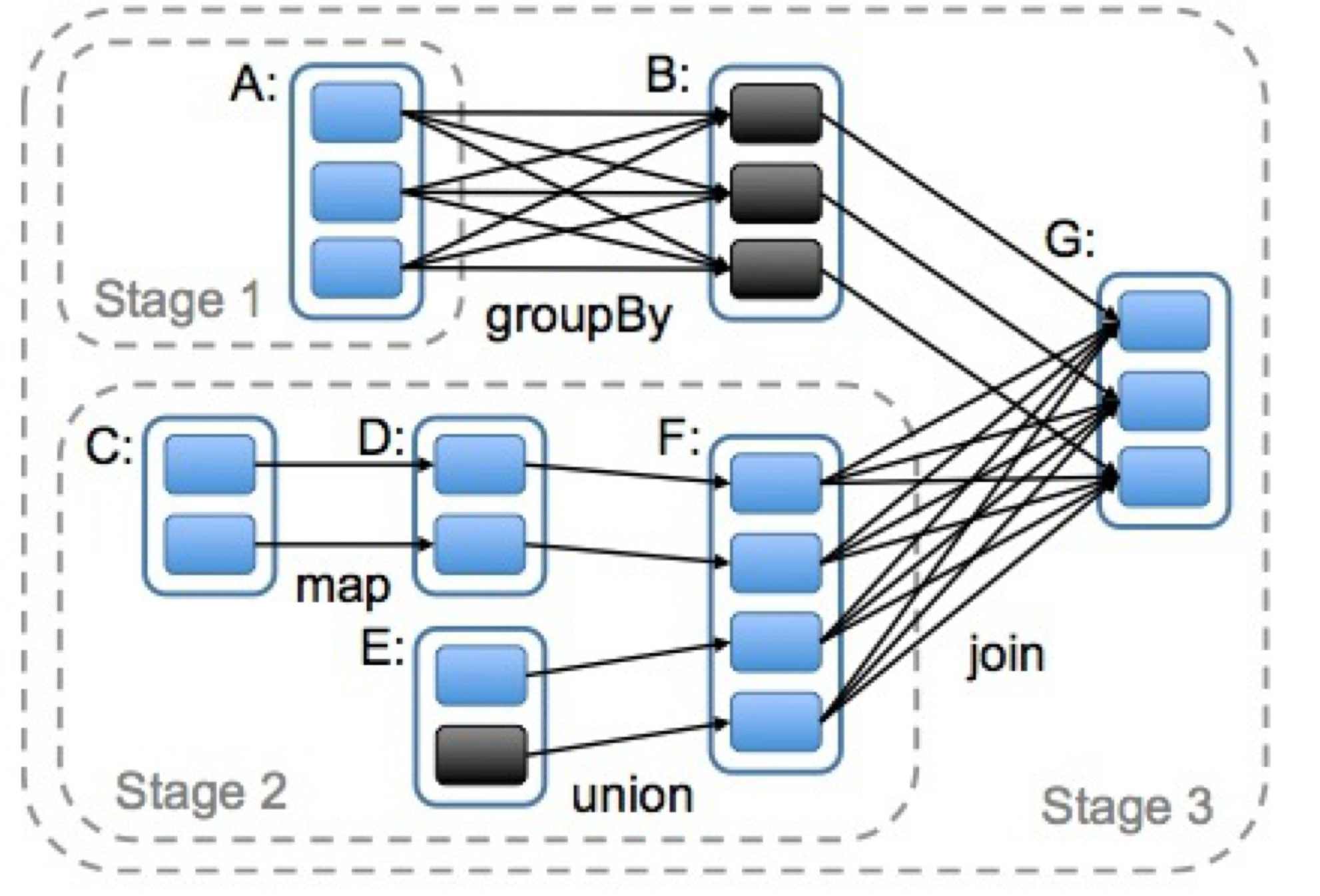
RDD任务的切分,分为:Application、Job、Stage和Task,而且每一层都是1对n的关系
4个名词
- Application:初始化一个SparkContext即生成一个Application
- Job:一个Action算子就会生成一个Job
- Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
- Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task。
个人理解
同样思考为啥要划分这么多东西?
- Application
一个spark不止跑一个程序吧,所以一个程序一个 Application理所当然,进而生成一个AppMaster管理它。
- Job
一个程序有许多转换算子和行动算子。只有执行到行动操作才真正改变数据,所以把截止到行动算子的算子划一个job合情合理吧。而且我们从源码也可以看到,执行一个行动操作,就会执行sc.runJob(...)
- Stage
在一个Job中,有的可一路执行到宽依赖的,不需要shuffle写磁盘,按这个划分为一个Stage。
- Task
在一个Stage中,我们观察最后一组分区,也就是shuffer前的,由于到这里都是可以一路执行的,所以按最后一组分区的个数,一个分区划一个Task。此时都划到分区了,自然不用划分了。