简介
使用spark时,针对大的、只读、大家都要用的变量,可以使用 broadcast 提高性能:
- 大的:对其切分后再传输
- 只读:只有
broadcast.value方法
- 大家都要用:同一个executor的task共享
流程
- broadcast 对象在driver端写入block中,较简单。
- 在executor端中读取时,流程复杂一点,如下图所示:
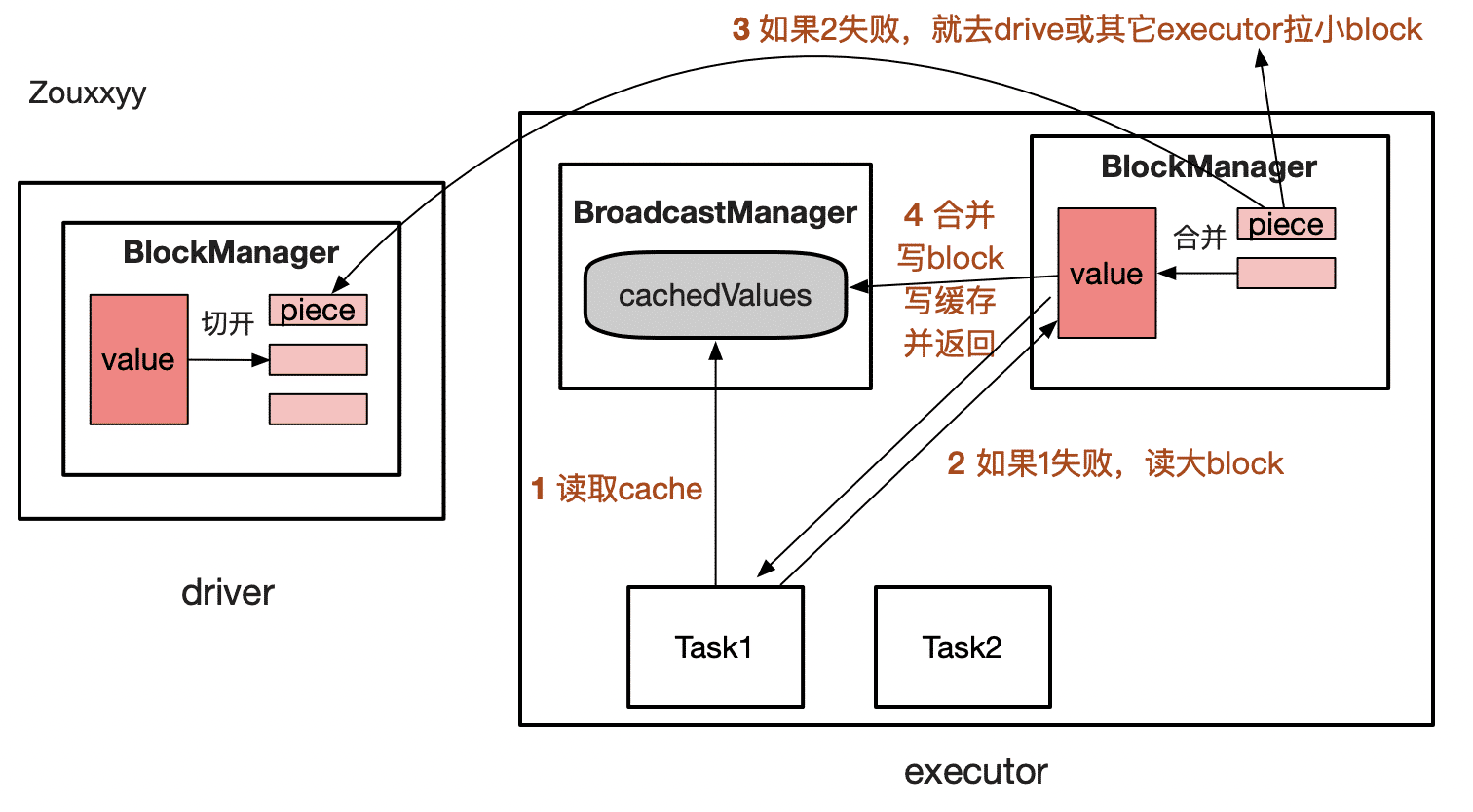
细节:
- 成功读到value后,会写入
cachedValues中(task共享),它可能会被垃圾回收,关注它的数据结构。
- broadcast对象的StorageLevel 是
MEMORY_AND_DISK
- 拉取block时,永远是拉小block(piece,默认4M)并且是乱序拉取,再合并。
sc.broadcast
使用sc.broadcast在driver端创建broadcast对象
val listBroadcast: Broadcast[List[String]] = sc.broadcast(listToRemove)
def broadcast[T: ClassTag](value: T): Broadcast[T] = {
assertNotStopped()
require(!classOf[RDD[_]].isAssignableFrom(classTag[T].runtimeClass),
"Can not directly broadcast RDDs; instead, call collect() and broadcast the result.")
val bc = env.broadcastManager.newBroadcast[T](value, isLocal)
val callSite = getCallSite
logInfo("Created broadcast " + bc.id + " from " + callSite.shortForm)
cleaner.foreach(_.registerBroadcastForCleanup(bc))
bc
}
def newBroadcast[T: ClassTag](value_ : T, isLocal: Boolean): Broadcast[T] = {
broadcastFactory.newBroadcast[T](value_, isLocal, nextBroadcastId.getAndIncrement())
}
override def newBroadcast[T: ClassTag](value_ : T, isLocal: Boolean, id: Long): Broadcast[T] = {
new TorrentBroadcast[T](value_, id)
}
|
TorrentBroadcast
TorrentBroadcast 继承 Broadcast,下面关注其构造流程
private val broadcastId = BroadcastBlockId(id)
@transient private lazy val _value: T = readBroadcastBlock()
@transient private var compressionCodec: Option[CompressionCodec] = _
@transient private var blockSize: Int = _
private def setConf(conf: SparkConf) {
compressionCodec = if (conf.getBoolean("spark.broadcast.compress", true)) {
Some(CompressionCodec.createCodec(conf))
} else {
None
}
blockSize = conf.getSizeAsKb("spark.broadcast.blockSize", "4m").toInt * 1024
checksumEnabled = conf.getBoolean("spark.broadcast.checksum", true)
}
setConf(SparkEnv.get.conf)
private val broadcastId = BroadcastBlockId(id)
private val numBlocks: Int = writeBlocks(obj)
private var checksumEnabled: Boolean = false
private var checksums: Array[Int] = _
|
writeBlocks
driver端将 value 写入block,再将 value 切开后再写入block,注意StorageLevel 都是 MEMORY_AND_DISK
至此Broadcast已经准备好。
private def writeBlocks(value: T): Int = {
import StorageLevel._
val blockManager = SparkEnv.get.blockManager
if (!blockManager.putSingle(broadcastId, value, MEMORY_AND_DISK, tellMaster = false)) {
throw new SparkException(s"Failed to store $broadcastId in BlockManager")
}
val blocks =
TorrentBroadcast.blockifyObject(value, blockSize, SparkEnv.get.serializer, compressionCodec)
if (checksumEnabled) {
checksums = new Array[Int](blocks.length)
}
blocks.zipWithIndex.foreach { case (block, i) =>
if (checksumEnabled) {
checksums(i) = calcChecksum(block)
}
val pieceId = BroadcastBlockId(id, "piece" + i)
val bytes = new ChunkedByteBuffer(block.duplicate())
if (!blockManager.putBytes(pieceId, bytes, MEMORY_AND_DISK_SER, tellMaster = true)) {
throw new SparkException(s"Failed to store $pieceId of $broadcastId in local BlockManager")
}
}
blocks.length
}
|
readBroadcastBlock
读取 Broadcast
val filterRDD: RDD[String] = rdd.filter(!listBroadcast.value.contains(_))
def value: T = {
assertValid()
getValue()
}
@transient private lazy val _value: T = readBroadcastBlock()
private def readBroadcastBlock(): T = Utils.tryOrIOException {
TorrentBroadcast.synchronized {
val broadcastCache = SparkEnv.get.broadcastManager.cachedValues
Option(broadcastCache.get(broadcastId)).map(_.asInstanceOf[T]).getOrElse {
setConf(SparkEnv.get.conf)
val blockManager = SparkEnv.get.blockManager
blockManager.getLocalValues(broadcastId) match {
case Some(blockResult) =>
if (blockResult.data.hasNext) {
val x = blockResult.data.next().asInstanceOf[T]
releaseLock(broadcastId)
if (x != null) {
broadcastCache.put(broadcastId, x)
}
x
} else {
throw new SparkException(s"Failed to get locally stored broadcast data: $broadcastId")
}
case None =>
logInfo("Started reading broadcast variable " + id)
val startTimeMs = System.currentTimeMillis()
val blocks = readBlocks()
logInfo("Reading broadcast variable " + id + " took" Utils.getUsedTimeMs(startTimeMs))
try {
val obj = TorrentBroadcast.unBlockifyObject[T](
blocks.map(_.toInputStream()), SparkEnv.get.serializer, compressionCodec)
val storageLevel = StorageLevel.MEMORY_AND_DISK
if (!blockManager.putSingle(broadcastId, obj, storageLevel, tellMaster = false)) {
throw new SparkException(s"Failed to store $broadcastId in BlockManager")
}
if (obj != null) {
broadcastCache.put(broadcastId, obj)
}
obj
} finally {
blocks.foreach(_.dispose())
}
}
}
}
}
|
readBlocks
从本地 or 远程(driver和其它executor)中拉取小blocks
private def readBlocks(): Array[BlockData] = {
val blocks = new Array[BlockData](numBlocks)
val bm = SparkEnv.get.blockManager
for (pid <- Random.shuffle(Seq.range(0, numBlocks))) {
val pieceId = BroadcastBlockId(id, "piece" + pid)
logDebug(s"Reading piece $pieceId of $broadcastId")
bm.getLocalBytes(pieceId) match {
case Some(block) =>
blocks(pid) = block
releaseLock(pieceId)
case None =>
bm.getRemoteBytes(pieceId) match {
case Some(b) =>
if (checksumEnabled) {
val sum = calcChecksum(b.chunks(0))
if (sum != checksums(pid)) {
throw new SparkException(s"corrupt remote block $pieceId of $broadcastId:" +
s" $sum != ${checksums(pid)}")
}
}
if (!bm.putBytes(pieceId, b, StorageLevel.MEMORY_AND_DISK_SER, tellMaster = true)) {
throw new SparkException(
s"Failed to store $pieceId of $broadcastId in local BlockManager")
}
blocks(pid) = new ByteBufferBlockData(b, true)
case None =>
throw new SparkException(s"Failed to get $pieceId of $broadcastId")
}
}
}
blocks
}
|
unpersist和destroy
unpersist(true) 和 destroy(true)
true : 表示删除时给block加锁
unpersist:删除executor上broadcast的缓存和block。 如果再次使用broadcast,则需要由driver重新发给executor。
destroy:听名字就知道,会干掉所有,包括driver中的。无法再次使用,调用isValid返回false。
补充知识
cachedValues
private[broadcast] val cachedValues = {
new ReferenceMap(AbstractReferenceMap.HARD, AbstractReferenceMap.WEAK)
}
|
cachedValues的数据结构是ReferenceMap,是Apache Commons Collections API中的对象。
基于hashmap实现,允许垃圾回收器删除映射。
StrongReference(强) > SoftReference(软) > WeakReference(弱) > PhantomReference(虚)
软引用:内存足够,GC时不回收此Object;内存OOM前,GC回收此Object。常用于Cache
弱引用:不管内存是否足够,GC时Object都会被回收
cachedValues 的 key是强引用,value是weak引用。因此value在GC时会被释放。如果以后又要用它,就再从block中读,然后再写入cachedValues(参照我画的图)。
小结
broadcast 相对简单,整体上看,就是将一个所有task都要用到的对象,写入BlockManager中,提高效率,节省内存。